
Research Progress
科研进展
-
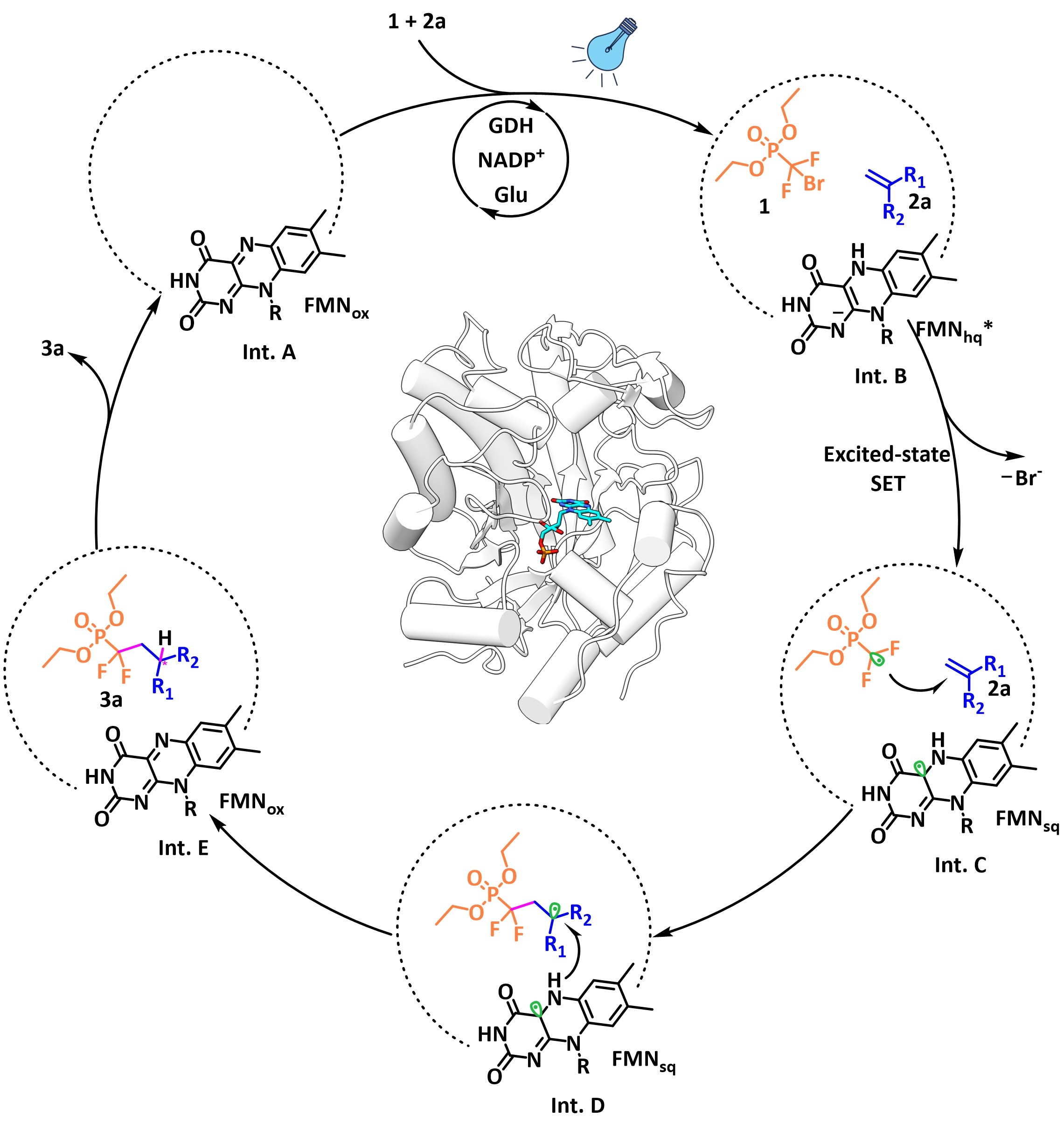 Angew VIP | 周佳海/古阳团队利用轻量化机器学习方法加速光酶进化实现含氟化合物的高效不对称合成含氟化合物是医药、农业和材料领域的关键结构单元,然而在温和条件下实现偕二氟基团的高选择性、可持续引入仍是一大挑战。近年来,光酶催化融合了光催化和生物催化的优势,为不对称合成提供了强有力的平台,其中黄素单核苷酸(FMN)依赖型“烯”还原酶(EREDs)备受关注。酶在长期的自然进化中形成了固有的底物特异性,直接用于非天然转化时效率较低。传统的定向进化方法通常需筛选数千至上万个突变体,耗时费力;而基于蛋白质语言模型(PLMs)的“零样本”预测在面对非天然自由基反应时,往往因缺乏特定的训练数据,难以准确建立序列与催化活性/选择性之间的映射关系。 针对上述挑战,中国科学院深圳先进技术研究院合成生物学研究所客座研究员/南京师范大学教授周佳海与团队副研究员古阳等提出了一种将活性口袋理性设计与机器学习模型相结合的小样本、加速进化策略,该成果以“Machine-Learning-Enabled Rapid Evolution of Photoenzymes for the Asymmetric Synthesis of gem-Difluorophosphonates”为题,作为VIP论文发表于《德国应...2026-07-10
Angew VIP | 周佳海/古阳团队利用轻量化机器学习方法加速光酶进化实现含氟化合物的高效不对称合成含氟化合物是医药、农业和材料领域的关键结构单元,然而在温和条件下实现偕二氟基团的高选择性、可持续引入仍是一大挑战。近年来,光酶催化融合了光催化和生物催化的优势,为不对称合成提供了强有力的平台,其中黄素单核苷酸(FMN)依赖型“烯”还原酶(EREDs)备受关注。酶在长期的自然进化中形成了固有的底物特异性,直接用于非天然转化时效率较低。传统的定向进化方法通常需筛选数千至上万个突变体,耗时费力;而基于蛋白质语言模型(PLMs)的“零样本”预测在面对非天然自由基反应时,往往因缺乏特定的训练数据,难以准确建立序列与催化活性/选择性之间的映射关系。 针对上述挑战,中国科学院深圳先进技术研究院合成生物学研究所客座研究员/南京师范大学教授周佳海与团队副研究员古阳等提出了一种将活性口袋理性设计与机器学习模型相结合的小样本、加速进化策略,该成果以“Machine-Learning-Enabled Rapid Evolution of Photoenzymes for the Asymmetric Synthesis of gem-Difluorophosphonates”为题,作为VIP论文发表于《德国应...2026-07-10 -
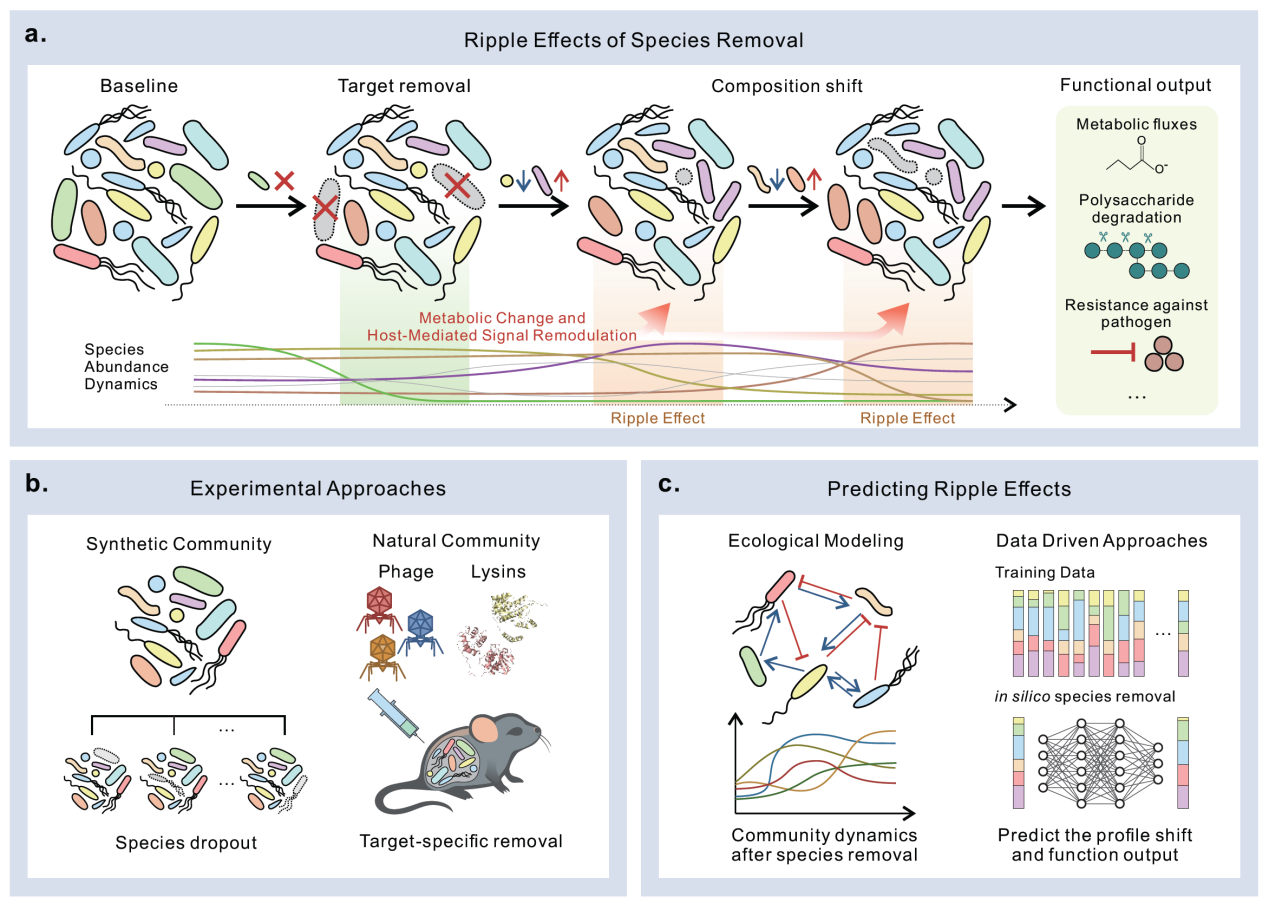 Cell Host & Microbe | 定量合成生物学全国重点实验室戴磊团队提出解码肠道菌群的"涟漪效应"近年来,靶向肠道菌群的调控已成为疾病治疗和健康干预的重要策略之一。然而,在肠道微生态这一复杂系统中,针对特定物种的扰动可能引起整个群落稳态的转变。如何理解和预测这一现象,是微生物组工程的重要科学问题之一。 2026年7月8日,中国科学院深圳先进技术研究院定量合成生物学全国重点实验室、合成生物学研究所戴磊研究员团队受邀在国际权威期刊Cell Host & Microbe发表题为“Understanding ripple effects in the gut microbiome”的观点文章(Forum article)[1]。文章从系统生物学视角出发,深入阐述了肠道菌群研究中被忽视的“涟漪效应(Ripple Effects)”:在高度互联的肠道微生态系统中,针对单一物种的靶向干预通过复杂的生态互作网络传播,可能引发群落结构与代谢功能的系统性重塑。文章从分子机制与生态机制两个层面系统阐述涟漪效应的形成规律,提出实验与模型相融合的研究范式,为微生物组精准调控提供了新的理论框架。 文章上线截图 原文链接:https://www.cell.com/cell-host-microbe/abstra...2026-07-09
Cell Host & Microbe | 定量合成生物学全国重点实验室戴磊团队提出解码肠道菌群的"涟漪效应"近年来,靶向肠道菌群的调控已成为疾病治疗和健康干预的重要策略之一。然而,在肠道微生态这一复杂系统中,针对特定物种的扰动可能引起整个群落稳态的转变。如何理解和预测这一现象,是微生物组工程的重要科学问题之一。 2026年7月8日,中国科学院深圳先进技术研究院定量合成生物学全国重点实验室、合成生物学研究所戴磊研究员团队受邀在国际权威期刊Cell Host & Microbe发表题为“Understanding ripple effects in the gut microbiome”的观点文章(Forum article)[1]。文章从系统生物学视角出发,深入阐述了肠道菌群研究中被忽视的“涟漪效应(Ripple Effects)”:在高度互联的肠道微生态系统中,针对单一物种的靶向干预通过复杂的生态互作网络传播,可能引发群落结构与代谢功能的系统性重塑。文章从分子机制与生态机制两个层面系统阐述涟漪效应的形成规律,提出实验与模型相融合的研究范式,为微生物组精准调控提供了新的理论框架。 文章上线截图 原文链接:https://www.cell.com/cell-host-microbe/abstra...2026-07-09 -
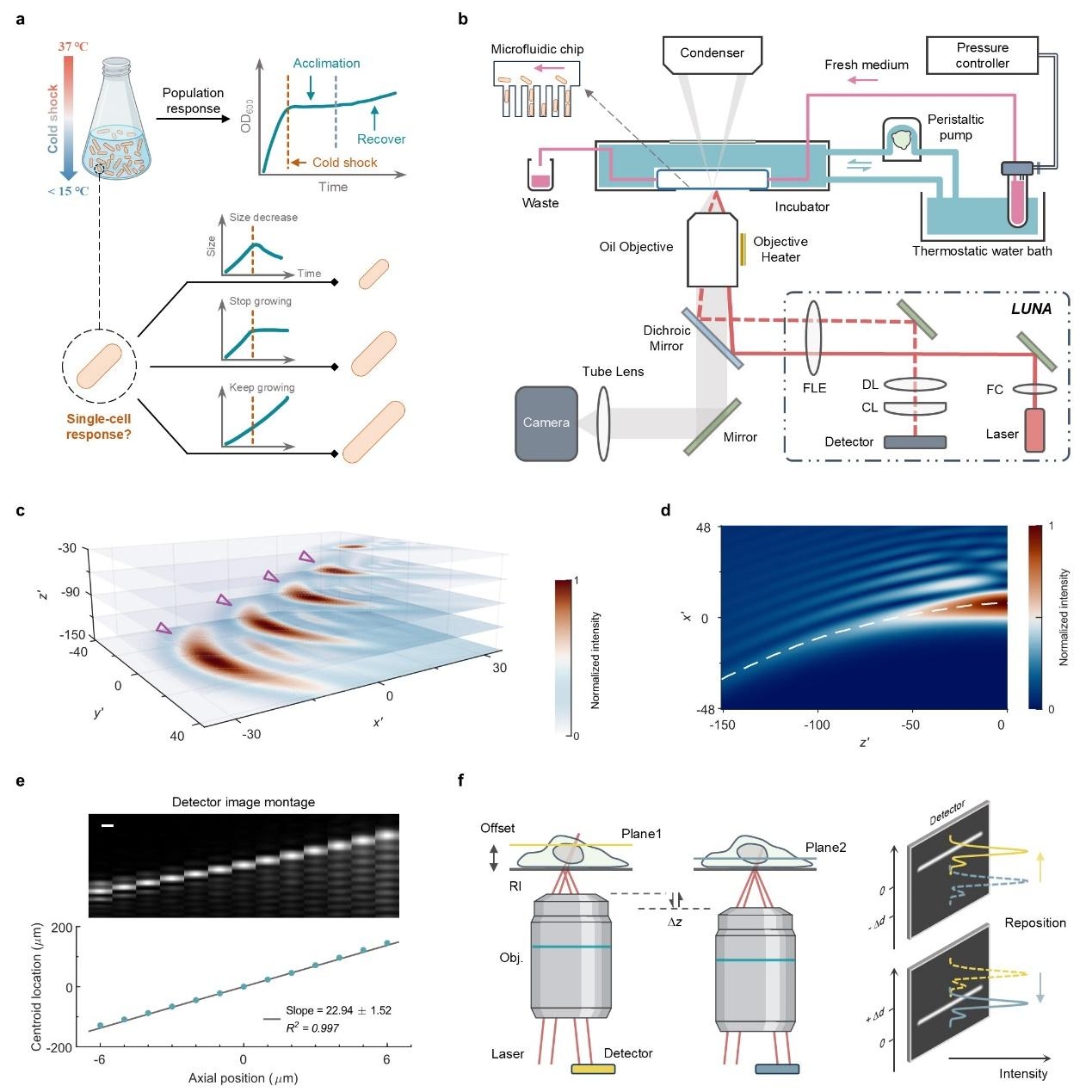 eLife|定量合成生物学全国重点实验室开发LUNA自动对焦系统,揭示细菌冷休克新机制细菌冷休克反应是微生物应对环境温度骤降的核心适应性机制,但其复杂的生理调控过程至今未被充分理解。长期以来,相关研究主要依赖群体水平测量,虽能揭示“生长停滞”等宏观特征,却难以通过在单细胞水平上开展高时空分辨的动态观测来深入解析冷休克反应的调控机制。然而,诱导冷休克所需的快速大幅降温会导致显微镜焦平面发生严重漂移,远超现有自动对焦技术的补偿能力,严重限制了对细菌低温适应机制的研究。 北京时间2026年7月7日,中国科学院深圳先进技术研究院定量合成生物学全国重点实验室/合成生物学研究所黄术强研究员团队,在eLife期刊发表了题为“A coma pattern-based autofocusing method resolves bacterial cold shock response at single-cell level”的重要研究成果。团队创新性地开发了一套名为LUNA(Locking Under Nanoscale Accuracy)的自动对焦系统,利用检测光的彗差图案来精确锁定焦平面,将显微镜的聚焦精度提升至3纳米以内,并将有效工作范围扩展至物镜焦深的40倍以上。借助LUNA,...2026-07-08
eLife|定量合成生物学全国重点实验室开发LUNA自动对焦系统,揭示细菌冷休克新机制细菌冷休克反应是微生物应对环境温度骤降的核心适应性机制,但其复杂的生理调控过程至今未被充分理解。长期以来,相关研究主要依赖群体水平测量,虽能揭示“生长停滞”等宏观特征,却难以通过在单细胞水平上开展高时空分辨的动态观测来深入解析冷休克反应的调控机制。然而,诱导冷休克所需的快速大幅降温会导致显微镜焦平面发生严重漂移,远超现有自动对焦技术的补偿能力,严重限制了对细菌低温适应机制的研究。 北京时间2026年7月7日,中国科学院深圳先进技术研究院定量合成生物学全国重点实验室/合成生物学研究所黄术强研究员团队,在eLife期刊发表了题为“A coma pattern-based autofocusing method resolves bacterial cold shock response at single-cell level”的重要研究成果。团队创新性地开发了一套名为LUNA(Locking Under Nanoscale Accuracy)的自动对焦系统,利用检测光的彗差图案来精确锁定焦平面,将显微镜的聚焦精度提升至3纳米以内,并将有效工作范围扩展至物镜焦深的40倍以上。借助LUNA,...2026-07-08
NEWS
新闻活动





Media attention
媒体关注
