
专家点评Nature Biomedical Engineering | 蛋白质语言模型跨越序列鸿沟,解锁远源抗菌肽
抗生素的长期过度使用正在加剧全球耐药危机,传统治疗手段的有效性持续下降。与此同时,畜牧业“减抗、限抗”政策深入推进,使养殖生产面临新的感染防控挑战。开发新型、安全、高效的抗菌分子,已成为医疗与农业领域共同面对的紧迫课题。
抗菌肽(Antimicrobial peptides,AMPs)是一类长度通常小于100个氨基酸的天然小分子多肽,广泛存在于动物、植物和微生物中,是先天免疫系统的重要组成部分。其通常通过膜破坏或多靶点机制发挥抗菌作用,耐药产生难度相对较低,并具有一定免疫调节潜力,被认为是理想的抗生素替代方向。然而,AMP规模化开发长期受制于发现效率低下。传统方法依赖序列同源性搜索或理化规则筛选,本质上是在已知AMP的“邻域空间”内进行局部扩展,难以识别进化上远源但可能具有高活性的全新序列。因此,突破“相似性驱动”的技术框架,建立对低同源甚至无明显同源序列的识别能力,成为该领域亟待解决的关键问题。
2026年3月3日,中国科学院深圳先进技术研究院(简称“深圳先进院”)定量合成生物学全国重点实验室、合成生物学研究所戴磊研究员课题组联合香港中文大学李煜教授团队,在Nature Biomedical Engineering发表了题为“Uncovering evolutionarily remote and highly potent antimicrobial peptides with protein language models”的研究论文。该研究开发了基于蛋白质语言模型和深度学习的抗菌肽挖掘新方法HMD-AMP,成功突破传统技术瓶颈,挖掘出大量进化远源、高活性且低毒性的抗菌肽,为新型抗菌药物研发提供了新策略和候选分子。

原文链接:https://doi.org/10.1038/s41551-026-01630-w
AI赋能AMPs识别:从“相似性搜索”到“语义理解”
研究团队开发了基于蛋白质语言模型的抗菌肽挖掘工具——HMD-AMP。该框架利用经短肽数据微调的蛋白语言模型ESM-2提取深层序列特征,并结合分层多任务深度森林分类器,构建了端到端预测体系(图1)。与传统方法不同,蛋白质语言模型无需依赖显式序列比对,而是通过大规模无监督学习捕捉蛋白序列中的“隐式语义表示”——即进化与结构层面的深层规律。HMD-AMP不仅能够精准区分抗菌肽与非抗菌肽,还能预测抗菌谱类型,实现更精细的功能评估。
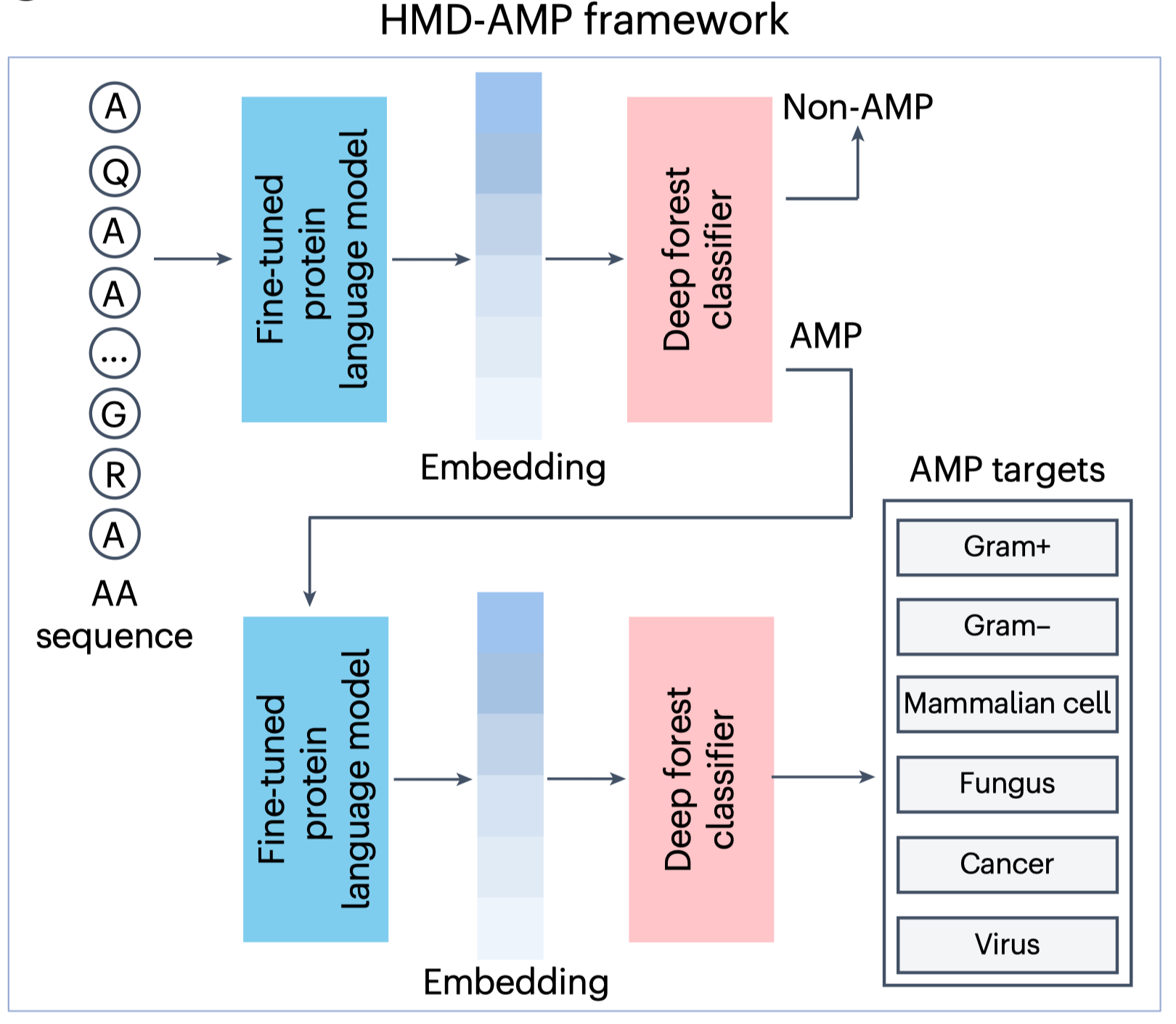
图1. HMD-AMP模型框架
在多项基准测试中,HMD-AMP均表现出优异性能。尤其在低序列相似性、低结构相似性的严苛测试条件下,其表现显著优于现有方法,达到国际先进水平(图2)。同时,模型预测分数能够有效反映实际抑菌活性,为高活性分子的快速筛选提供可靠依据。
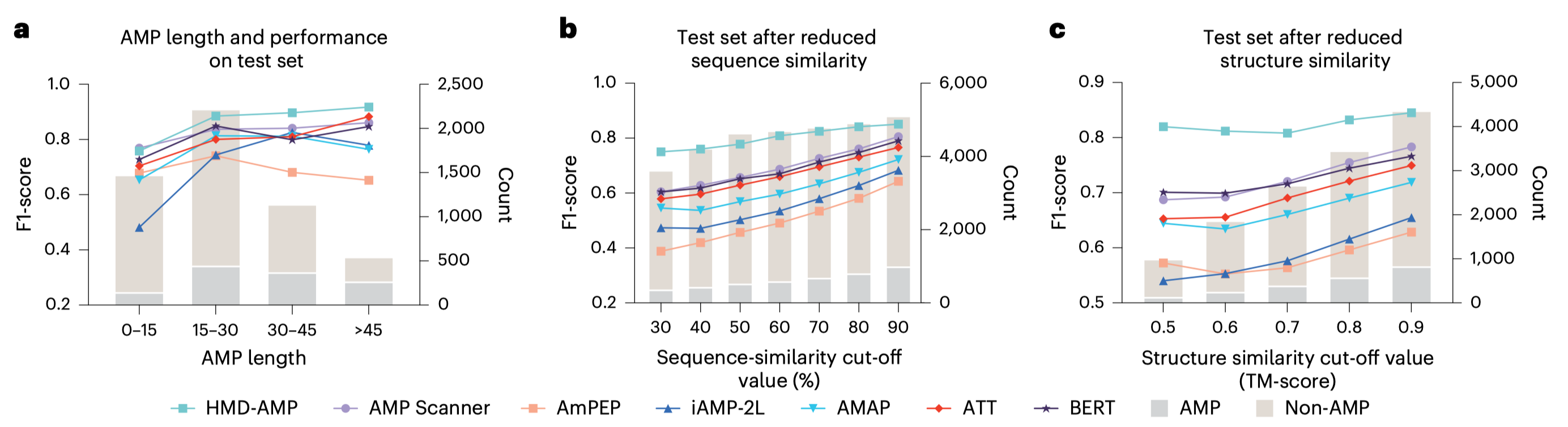
图2. HMD-AMP在多种测试中表现优异
3700万条候选序列:大规模远源AMP挖掘
为验证模型在真实场景中的能力,研究团队将HMD-AMP应用于来自9种哺乳动物肠道的1850个微生物基因组,成功预测出超过3700万条抗菌肽候选序列,其中大部分与已知AMP序列相似性低于40%。在猪肠道微生物组及宿主基因组中,团队从超过14亿条肽序列中筛选出7647条候选序列。经实验验证,62条高置信候选中有52条表现出显著抗菌活性,阳性率达84%。其中30条为序列新颖的远源AMP(与模型训练集序列相似度<40%),4条与已知AMPs序列相似性不足10%(图3)。进一步的跨宿主验证显示,在其他哺乳动物肠道来源的29条候选中,有22条表现出良好抗菌活性,其中18条为远源新序列。
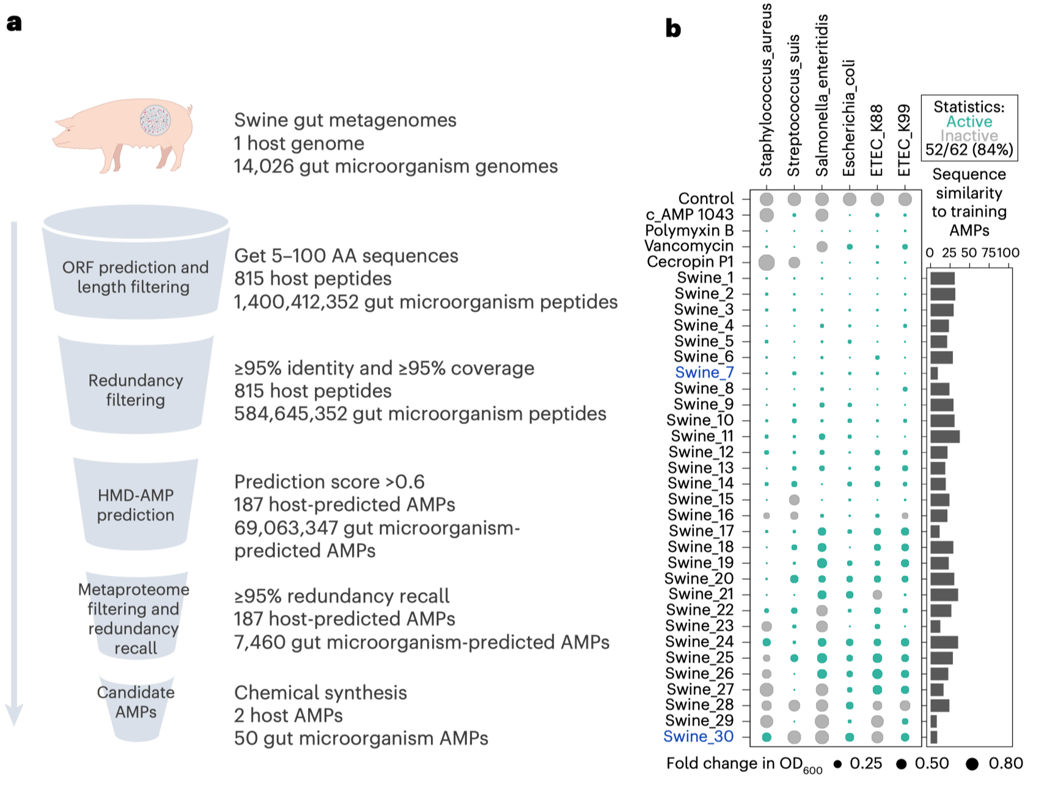
图3. 对猪肠道微生物组和宿主基因组进行AMPs挖掘
在74条经验证的AMP中,48条为序列新颖的远源AMP。这些分子虽然序列差异显著,但保留了典型AMP的结构折叠和功能基序,说明模型捕捉到了进化过程中保守的功能特征,而非简单的表面序列模式(图4)。

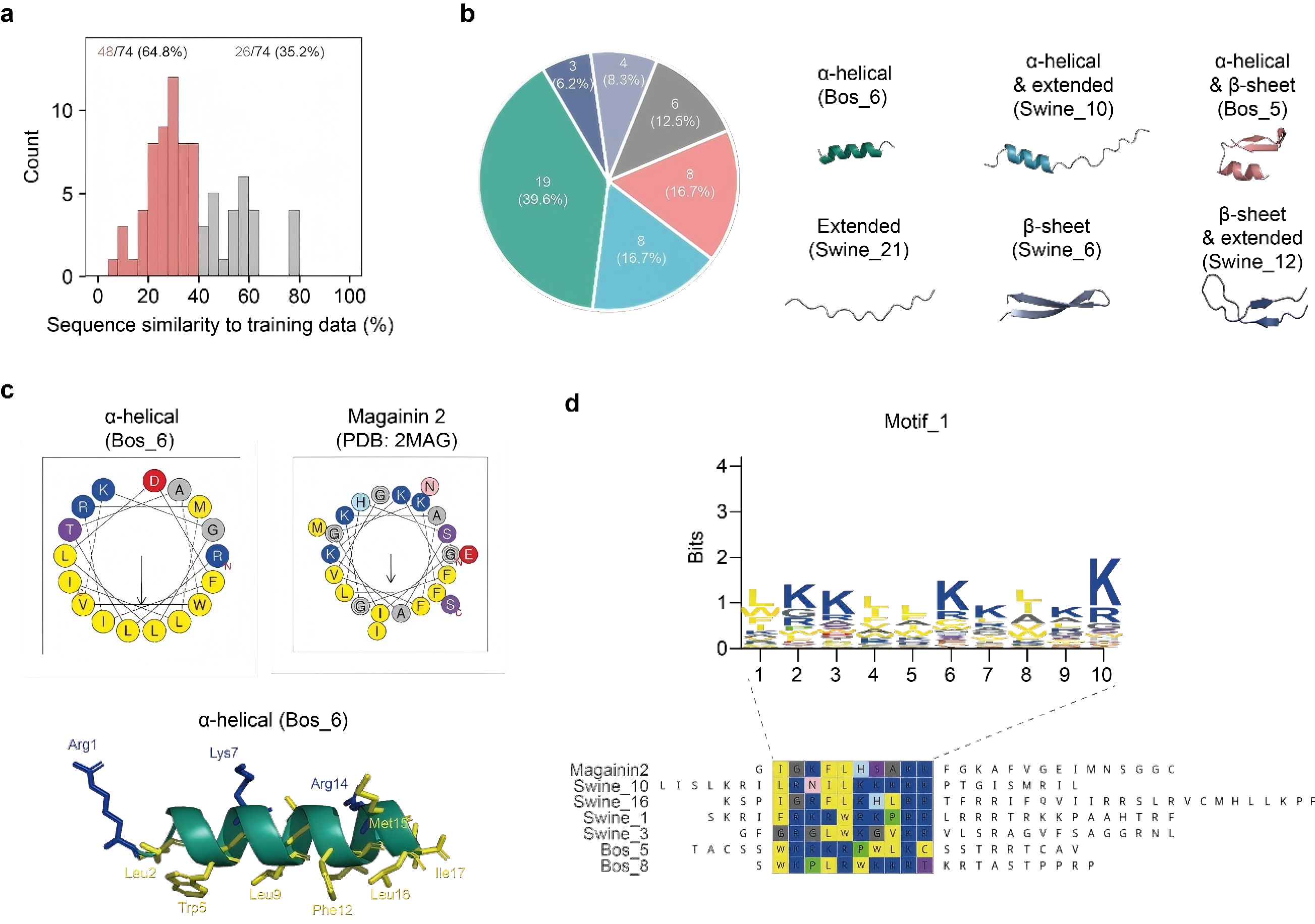
图4. 本研究发现的远源AMPs的结构和序列特征
研究团队对14条活性较高的AMP进行了深入评估。结果显示,其中8条(含4条远源新序列)的抗菌活性可与多粘菌素B、万古霉素等临床药物相媲美。溶血与细胞毒性实验表明,这些高活性AMP未表现出明显毒性,显示出良好的安全性(图5)。值得关注的是,抗菌肽Swine_2在小鼠腹膜炎模型中显著提高感染小鼠存活率,验证了其体内治疗潜力。
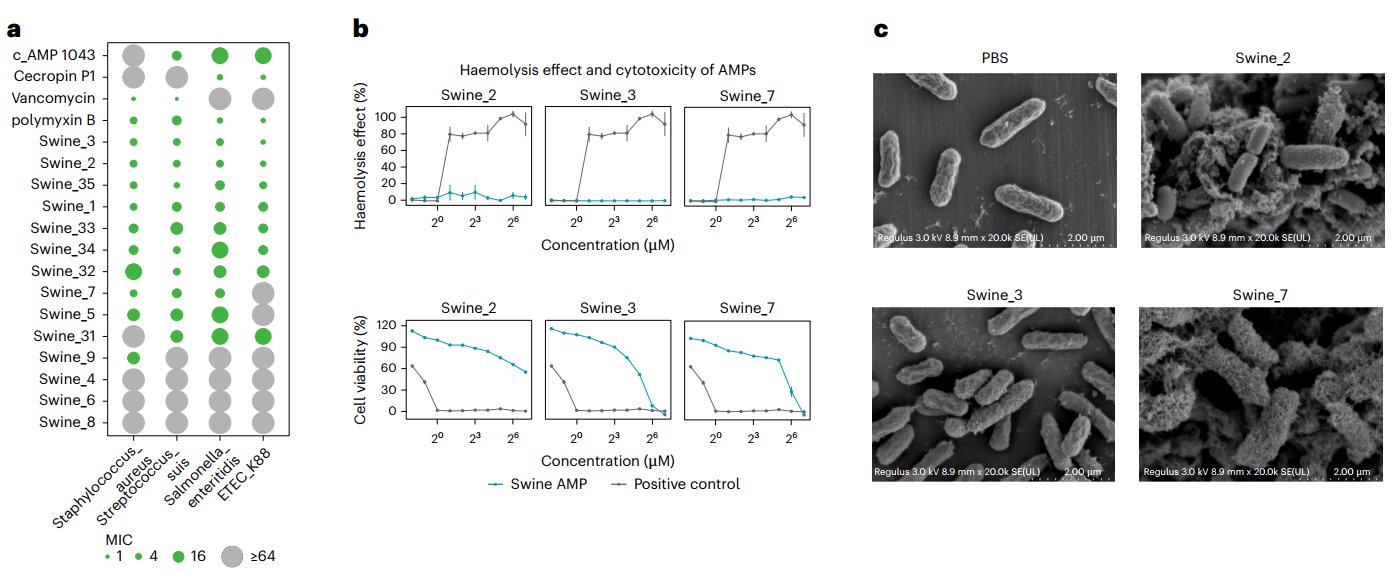
图5. 本研究发现的AMPs杀菌活性与安全性评估
该研究的核心创新在于,将蛋白语言模型的进化特征捕捉能力与深度学习框架相结合,首次实现对进化远源抗菌肽的系统性挖掘,突破了传统方法依赖序列同源性的限制。同时,研究系统挖掘了哺乳动物宿主及肠道微生物组中的抗菌肽资源,发现宿主来源AMP往往兼具高活性与低毒性优势,为新型抗菌药物开发提供了重要资源。未来,若进一步结合肽稳定性优化、递送系统改造及体内安全性提升策略,这些远源AMP有望在人类医疗与畜禽养殖等领域实现转化应用,为应对全球抗生素耐药危机提供新的技术路径。
深圳先进院合成所戴磊研究员和香港中文大学李煜教授是本研究的共同通讯作者。香港中文大学余沁泽博士与深圳先进院合成所副研究员刘红宾博士、施海梅博士是本研究的共同第一作者。该项研究成果获得国家重点研发计划、国家自然科学基金、深圳市医学研究专项资金以及深圳合成生物学创新研究院等项目的资助。
专家点评
谯仕彦(中国工程院院士,中国农业大学)
抗菌肽在农业、食品安全、生物医药等领域的重要性持续上升。尤其在畜牧业“减抗、限抗”政策深入推进、耐药菌加速扩散的背景下,传统抗生素依赖模式正面临系统性挑战。相较于传统小分子抗生素,抗菌肽多通过膜破坏或多靶点机制发挥作用,耐药产生难度相对较高,并具备一定免疫调节潜力,因此被视为抗生素替代的重要方向。然而,抗菌肽应用的关键瓶颈在于发现策略的局限。传统方法主要依赖序列同源性搜索或理化特征规则筛选,本质上是在已知抗菌肽序列的“邻域空间”内做局部扩展,其有效性高度依赖数据库覆盖度。对于进化快速、序列高度多样的短肽而言,这种“相似性驱动”范式存在天然盲区,难以识别远缘的功能序列。与此同时,宿主基因组与复杂微生物组中蕴含大量未注释短肽,可能包含丰富的潜在抗菌资源。因此,从广泛生物来源系统性挖掘新颖序列,并建立对低同源序列的识别能力,成为该领域亟待突破的核心技术缺口。
香港中文大学李煜教授与中国科学院深圳先进技术研究院戴磊研究员团队的工作具有明确的问题导向和方法学创新意义。该研究引入预训练蛋白质语言模型,将大规模无监督学习所获得的深层序列表示用于抗菌肽功能预测,实现了从“显式相似性检索”向“隐式语义表征推断”的转变。该工作显著拓展了可探索的序列空间边界,使模型能够识别低同源性的远缘抗菌肽序列,突破传统方法的局限。该研究验证了预测方法在猪、牛等不同哺乳动物基因组和宿主共生微生物组的可迁移性,有望成为功能多肽发现与应用的重要技术引擎。